 ·
5 minute read
·
5 minute read
As covered in our Enterprise Airtable Architecture Foundations, the record limit is rarely the first thing that breaks in a scaling Airtable environment. But it is almost always what forces the conversation about data architecture that should have happened at the design stage.
By the time that conversation happens, the organization has usually already lost something more operationally damaging than performance: the ability to answer historical questions about its own business. When a CFO requests a three-year revenue trend broken down by client segment, or a compliance team needs a full audit trail of every closed contract from the previous fiscal year, the answer in most ungoverned Airtable environments is a version of "we don't have that anymore" or "it exists somewhere across four different bases, but nothing connects them."
That is the failure Data Tiering Architecture addresses. Not performance in isolation, but the systematic loss of historical data integrity that happens when no architectural decision is made about where data goes after it stops being active.
What Builders Get Wrong About Record Lifecycle
Airtable is engineered as a relational execution engine, optimized for active operational data. The expectation built into that design is that record lifecycle management is an architectural responsibility, meaning a decision the builder makes, not a feature the platform provides.
Most builders do not treat it that way. They treat the base as permanent storage by default, accumulating every record ever created with no removal protocol, and discover the cost only when performance degrades visibly or the record limit appears as a warning. At that point, as established in Architectural Complexity, the instinct is to split bases, which trades a monolith problem for a fragmentation problem without resolving the underlying absence of lifecycle governance.
A record created three years ago for a project that closed the following month and a record created this morning for a project going live next week sit in the same table, contribute to the same rollup recalculations, appear in the same automation trigger scope, and consume the same record count. That equivalence is not a constraint; it is a default that the architect is responsible for overriding through deliberate structural decisions.
What Data Tiering Actually Means in Airtable
Data Tiering is a standard infrastructure concept: different categories of data have different access patterns and different value to active operations, and should be stored in environments optimized for those specific patterns rather than in a single undifferentiated system. Applied inside Airtable's ecosystem, this means three categories with distinct handling requirements.
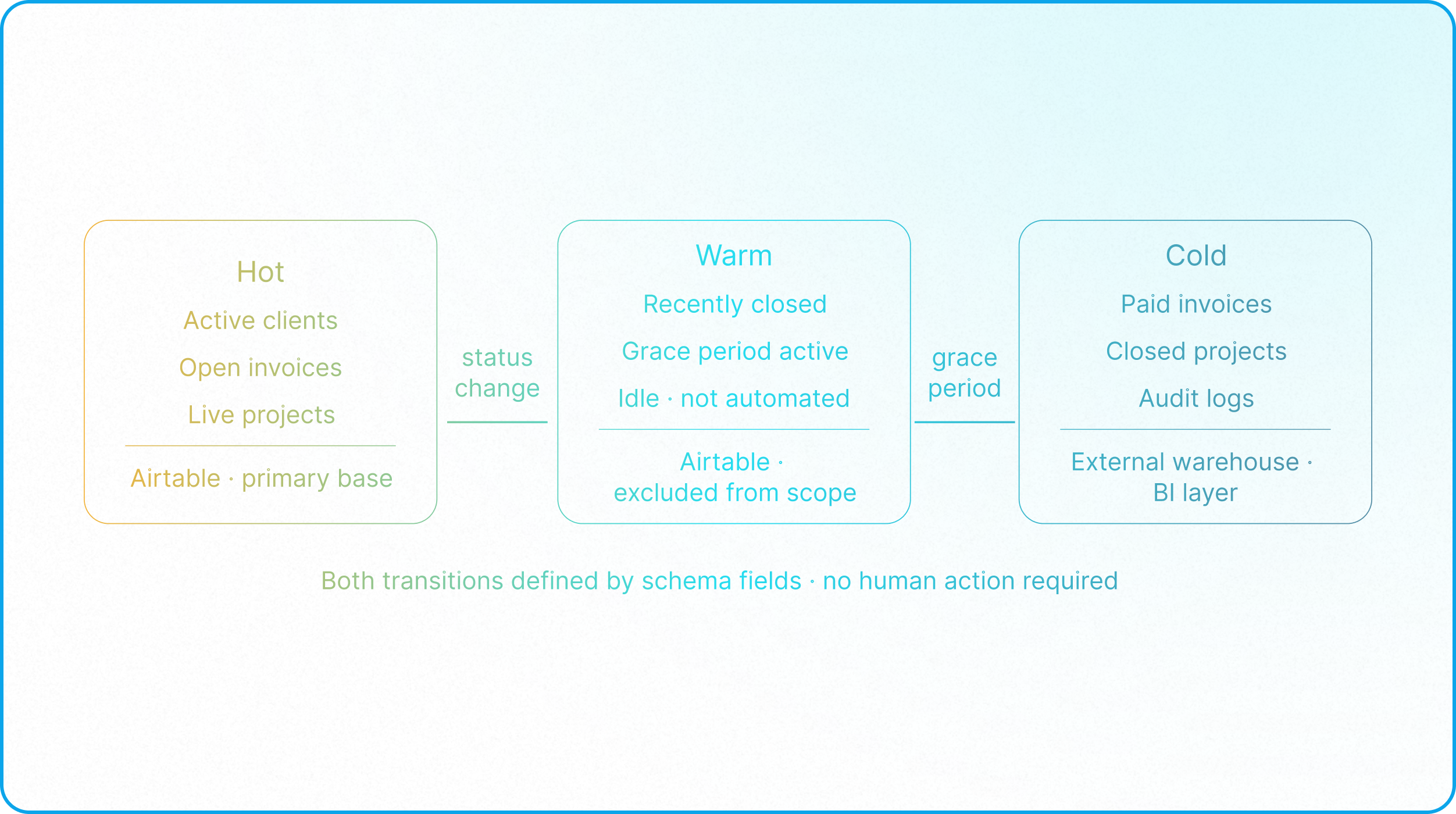
Hot data belongs in the primary Airtable base. Active clients, ongoing projects, open invoices, current deliverables. This is the data that automations fire against, Interfaces surface, and operators interact with every day. The schema discipline established in Database Normalization is what keeps this tier fast and governable regardless of how much hot data volume grows, because normalization ensures the computation surface stays proportional to actual operational activity.
Warm data has crossed a terminal status boundary but has not yet cleared the grace period that justifies external offload. A project closed yesterday is still warm, because it is likely to be referenced in the immediate aftermath of closure: final invoicing, retrospectives, and reactivation conversations. Warm records remain in the primary base but are excluded from the active automation scope and active Interface views. They are present but idle, carrying a timer toward their exit.
Cold data belongs outside Airtable entirely. Once a record has cleared its grace period, it has no remaining operational purpose inside the execution engine. Keeping it in the primary base is a pure computational cost with no corresponding operational value: it inflates rollup scopes, widens automation trigger windows, and occupies record count against a limit that the hot and warm tiers should own entirely. Cold data is moved to an external warehouse, where it can be queried for historical analysis and compliance without burdening the operational layer.
The two boundaries, Hot to Warm and Warm to Cold, are defined by fields in the schema, not by human judgment. A status field determines when a record becomes warm; a formula calculating elapsed days since that status was set determines when it becomes cold. Both transitions are automatic. Neither depends on an operator remembering to act, which is precisely the point: as established in Zero-Maintenance Architecture, the architectures that require the least maintenance are those where lifecycle discipline is baked into the schema rather than delegated to human initiative.
Why the Archive Base Is Not a Solution
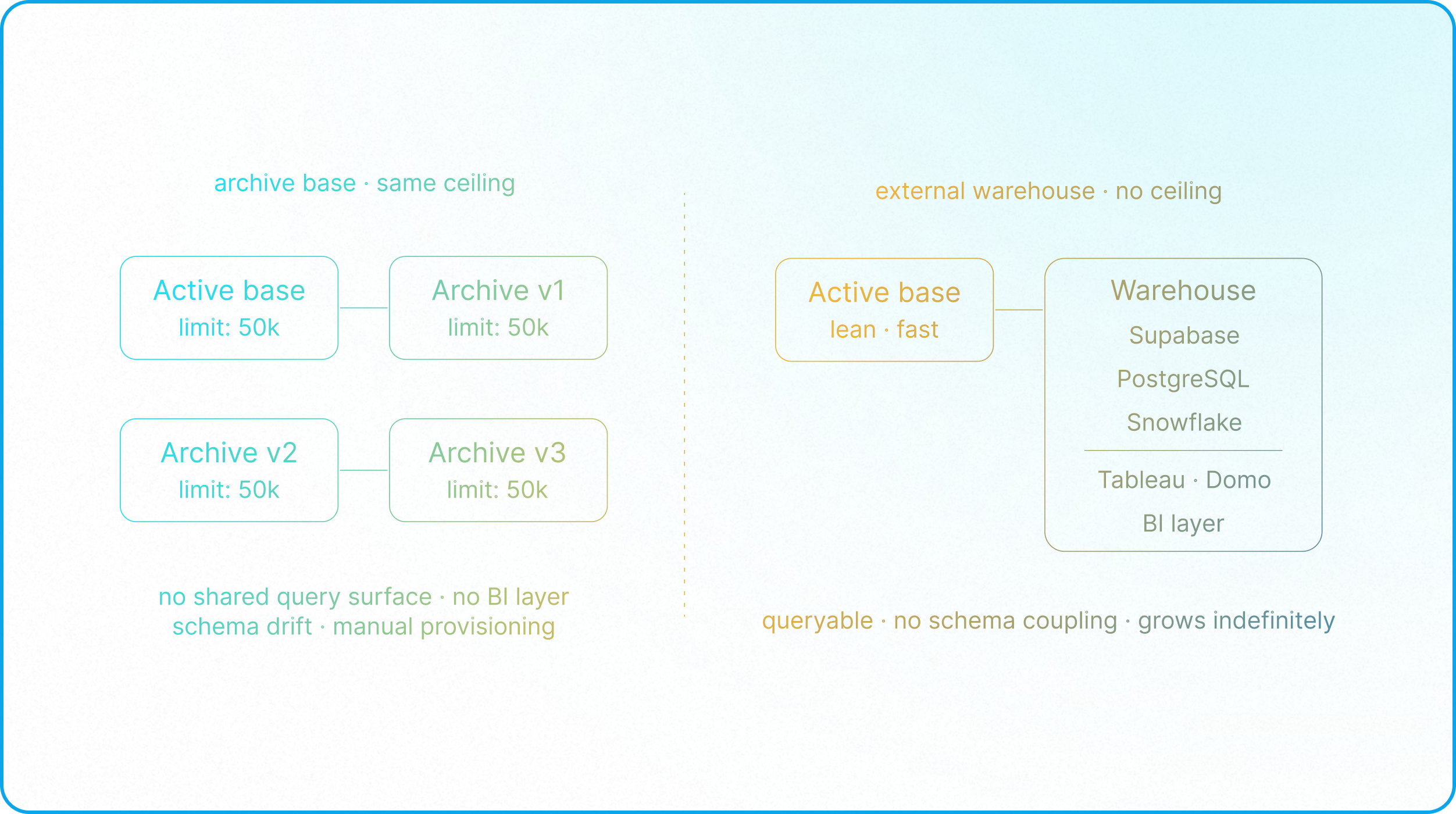
The most common builder response to accumulating cold data is to create a dedicated Airtable archive base. This appears logical, is straightforward to build, and fails reliably at scale for reasons that are structural.
Airtable does not expose base creation through its automation or API layer, meaning bases cannot be created programmatically. Every archive base requires manual provisioning, which means the archival discipline depends entirely on human initiative at exactly the moment the team is under the most operational pressure from closed records accumulating.
An archive base carries the same record limits as any other Airtable base. Moving records there shifts the ceiling; it does not eliminate it. As volume continues, teams find themselves managing multiple disconnected archive bases, none of which share a queryable surface and none of which connect to a BI layer, producing the exact fragmentation problem that Single Source of Truth Architecture identifies as the primary cause of reporting failure at enterprise scale.
Furthermore, as discussed in Architectural Complexity, Airtable-to-Airtable archiving suffers from the same vulnerability as native base syncs: any change to field configurations must be manually duplicated across the destination base, or the copy automations will break. If you alter field options or modify relationships in your active base, you must immediately mirror those changes in your archive base. External cold storage bypasses this vulnerability entirely. Because warehouses typically ingest historical data fields as raw text or schema-less JSON, they absorb schema modifications gracefully without breaking the transfer pipeline, freeing you from dual schema maintenance.
The Governed Offload Pipeline
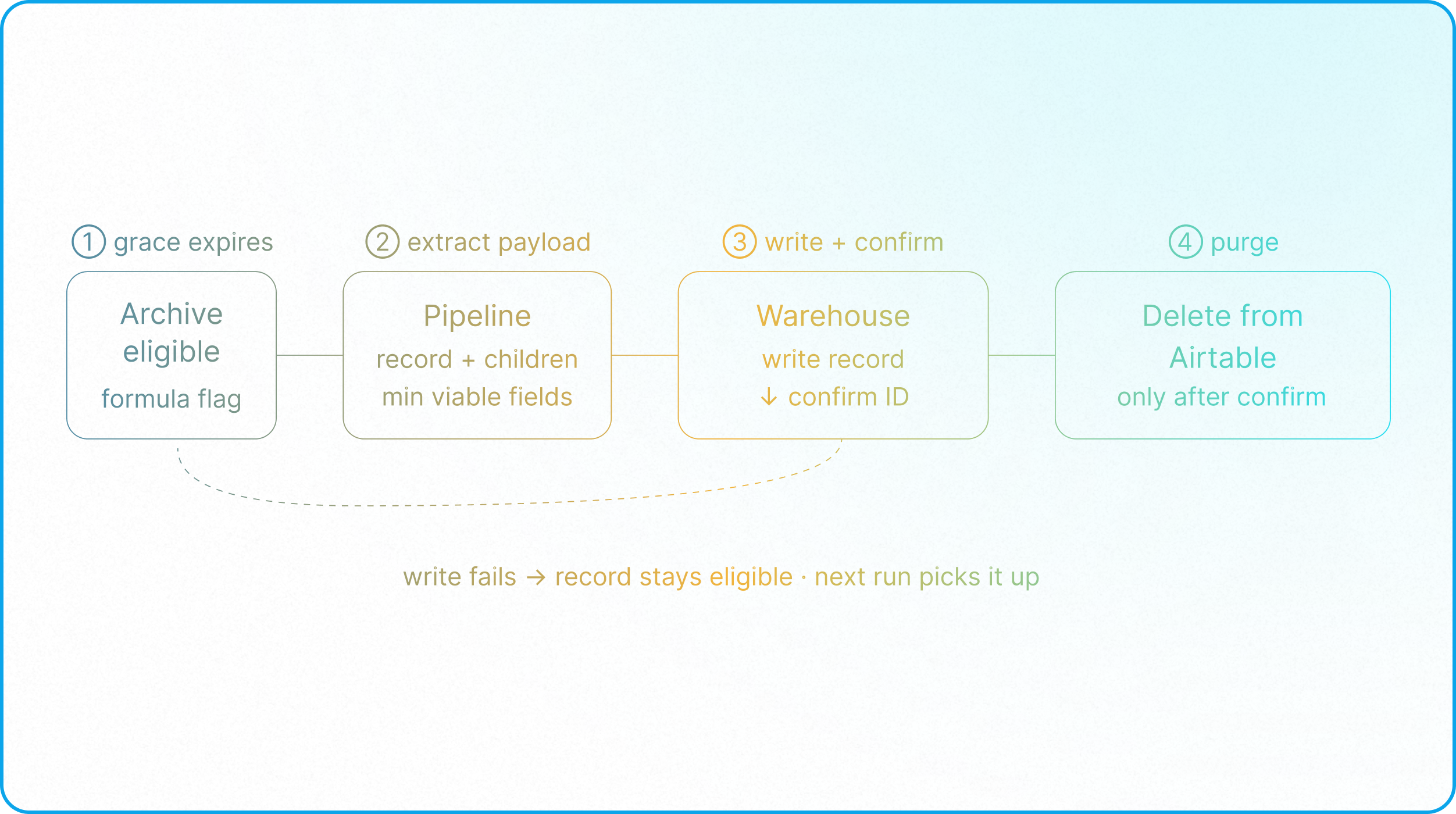
The transition from warm to cold is a governed, automated pipeline with one non-negotiable constraint: no record is deleted from the primary Airtable base until its successful creation in the external warehouse is confirmed.
The pipeline operates in sequence. The record reaches terminal status via a governed Interface or automation. A formula field begins calculating elapsed days. Once the grace period threshold is crossed, a scheduled automation flags the record as archive-eligible and fires a payload, scoped to only the fields required for historical completeness, to the integration layer. This payload discipline follows the same Minimum Viable Sync principles established in Airtable Sync as a Structural Bridge: every field in the payload must be there because the warehouse needs it, not because it exists in the source table.
The integration layer, operating either through a custom Airtable scripting action or via middleware like Make or n8n, writes the record to the external warehouse. The warehouse returns a confirmation with the assigned external ID. Only after that confirmation is received does the pipeline update the source record to "Archived" and authorize deletion.
A deletion without a confirmed write is data loss, not archival. Any failure at the warehouse write stage leaves the source record intact and archive-eligible, where the next scheduled run picks it up rather than removing it from the system. This sequence is invisible to operational users: the Interface through which a project is closed does not change, and the record exits active views on its scheduled timeline without any operator action beyond the original status change.
Where Cold Data Lives and What It Unlocks
The external warehouse selection is driven by compliance requirements and reporting use cases.
Supabase provides a fully managed PostgreSQL environment with SQL querying, API-based retrieval for individual record lookups, and native connectivity to BI tools. For organizations that need to surface historical records in response to specific queries, such as every contract delivered to a specific client over a defined period, Supabase handles that workload without any of it touching the primary Airtable base.
AWS S3 combined with DynamoDB or RDS is the standard for regulated industries where records must meet defined retention periods, encryption requirements, and geographic storage rules with an auditable chain of custody.
In all configurations, the cold warehouse connects to a BI layer such as Tableau or Domo, where longitudinal analysis runs against the full historical dataset without the primary base ever holding those records. Revenue trends across fiscal years, cohort analysis of churned accounts, project delivery pattern reporting: these are analyses that the operational base was never meant to support natively, and which become straightforwardly available the moment cold data has a proper home.
This is the structural inversion that Data Tiering produces. The primary Airtable base gets faster and more governable as the organization grows, because every record that exits the hot tier removes computation weight rather than adding it. The historical dataset gets richer and more queryable over time, because every archived record contributes to a warehouse designed for exactly that access pattern. The two systems do opposite jobs, and the architecture lets each of them do that job without the constraints of the other. Schedule a Discovery Call with InAir to map the terminal state definitions, grace period thresholds, and warehouse requirements specific to your entity classes.


