 ·
8 minute read
·
8 minute read
Enterprise software engineering did not begin with no-code platforms. Decades before Airtable existed, database engineers were solving the same challenges that every high-scale information system demands: how to maintain data consistency across distributed nodes, how to evolve a live schema without disrupting downstream systems, and how to design background processes that are resilient to failure.
The Airtable operations leader many times has deep platform intuition but no formal database engineering framework to anchor it. The software engineer, on the other hand, has a rigorous engineering framework but might underestimate how directly it maps to a governed Airtable environment. The most resilient enterprise architectures emerge when both perspectives are brought to the table simultaneously, built by professionals who understand the foundational principles of traditional software architecture (like the CAP Theorem, ACID compliance, the Data Contract, and Schema Migration) and know precisely how those principles map to Airtable's constraints.
As outlined in our Enterprise Airtable Architecture Foundations, the enterprise architect's job is not to work around Airtable's platform constraints. It is to understand them with the same rigor a database engineer applies to PostgreSQL or SQL Server, and design the system accordingly.
This is not a guide to normalization, covered in depth in Why Database Normalization is Non-Negotiable. This is also not a guide to relational mechanics (Primary Keys, Linked Records, and Junction Tables), which were established in The Mechanics of Relational Data. This is the next level: the engineering principles that senior architects use to protect live systems from invisible risk and the exact way they apply to the Airtable environment you are operating in right now.
Mental Model 1: The CAP Theorem — Choosing Between Consistency and Availability
In distributed systems, the CAP Theorem (formalized by computer scientist Eric Brewer at UC Berkeley) states that any distributed data store can only guarantee two of the following three properties simultaneously:
- Consistency: Every read returns the most recent write.
- Availability: Every request receives a response (even if it's not the most recent data).
- Partition Tolerance: The system continues operating even if network communication fails between nodes.
This is not a theoretical concern. Every enterprise Airtable ecosystem is, by definition, a distributed system. In fact, even within a single base, the moment you create a linked record field to another table, you are logically operating across multiple entity nodes. Once you deploy a multi-base architecture using cross-base syncs as we explored in Single Source of Truth Architecture, these boundaries physically expand into separate, distributed data nodes.
How the CAP Trade-Off Shapes the Architect's Design
In any distributed system, Availability and Consistency must be balanced by design, never by accident. The architect's first responsibility is to understand which category each data workflow falls into before a single base is configured.
The CAP trade-off in an Airtable ecosystem is not abstract. Consider a concrete scenario: an Account Manager closes a deal and updates the client status from "Negotiating" to "Active" in the Parent Vault at 9:00 AM. At 9:02 AM, the Finance team runs their billing workflow from their Child Base. If the sync cycle has not yet propagated that status change, Finance is about to generate an invoice for a client that the system still considers "Negotiating." No one made a mistake. No system failed. The architecture simply was not designed to handle the consistency requirement of that specific workflow.
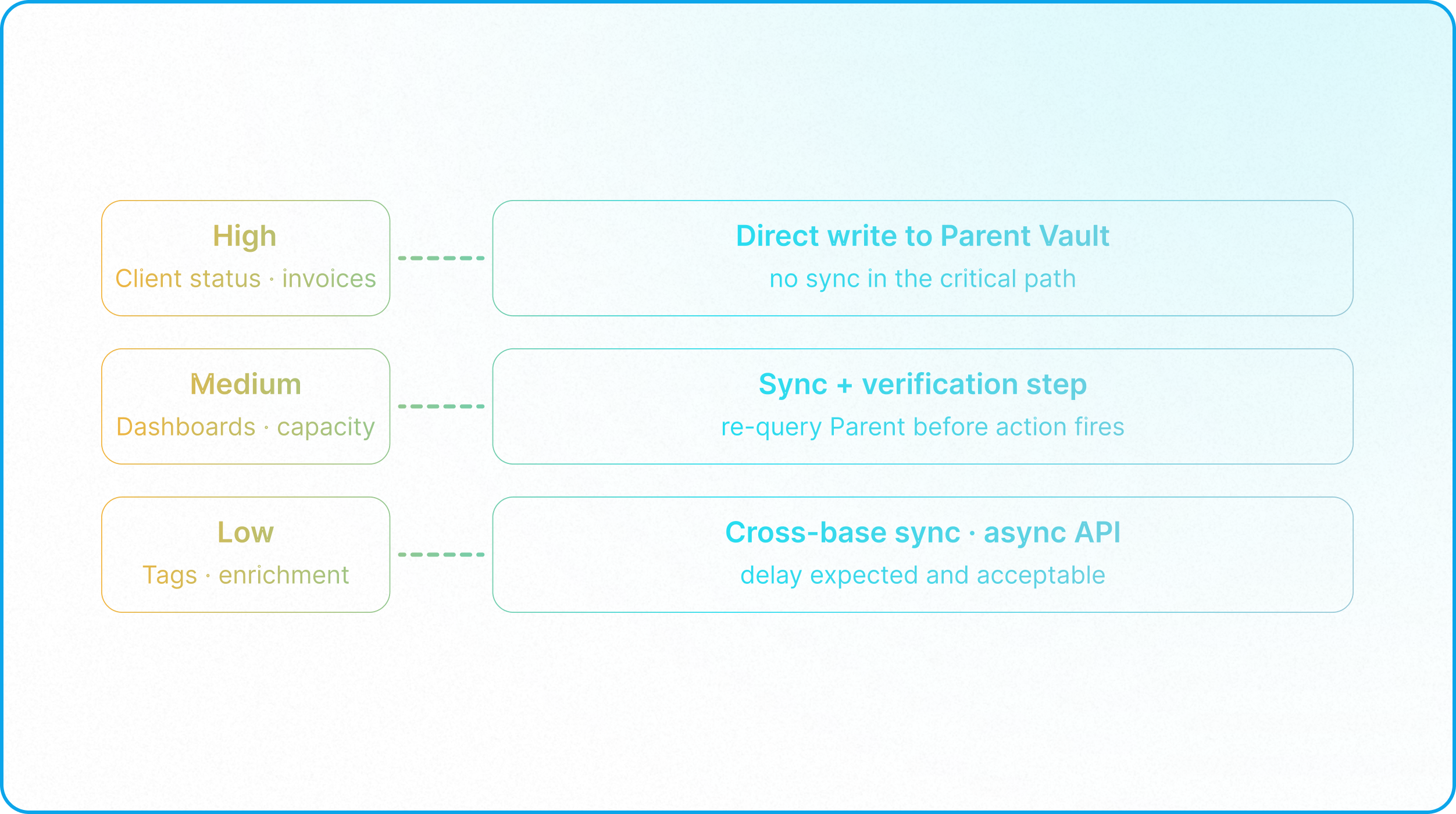
This is the CAP trade-off made concrete. The architect must classify each workflow by its tolerance for this window:
High Consistency Requirement: These workflows must write directly to the Parent Vault via a governed form or a live Interface, and read directly from it using native Lookup or Rollup fields. This ensures operators always interact with the authoritative, real-time state of the record, completely avoiding the network latency and margins of error introduced by external API scripts.
Medium Consistency Requirement: Operational dashboards, project status views, and team capacity reports can tolerate a short lag. For these, cross-base sync is appropriate, but the architect should implement a Verification Automation: a lightweight script that, before a downstream action fires, re-queries the Parent Vault via API to confirm the record's current status. This adds one layer of protection without requiring every workflow to bypass the sync entirely.
Low Consistency Requirement: Marketing attribution tags, campaign metadata, and non-critical enrichment data have no irreversible consequences if they are slightly delayed. Because these fields are typically read or written via third-party integrations, background automations, or external APIs (such as UTM trackers or CRM connectors), propagation delay is expected and acceptable. Cross-base sync or asynchronous API integration is the correct and efficient architecture here.
The consistency classification is not a technical decision alone; it requires a business policy decision about what constitutes an acceptable data lag for each department.
The Architect's Decision Framework
Before deploying a distributed Airtable architecture, the enterprise architect must explicitly classify each data flow by its Consistency Requirement:
|
Data Category |
Consistency Requirement |
Recommended Architecture |
|---|---|---|
|
Client Status Updates |
High |
Direct API write to Parent Vault only |
|
Invoice Totals |
High |
Native Rollup, no sync dependency |
|
Marketing Campaign Tags |
Low |
Cross-base sync acceptable |
|
Project Status Views |
Medium |
Sync with verification automation |
This classification exercise, which must happen before any base is configured, puts the architect in the exact decision-making posture a senior distributed systems engineer would apply to any enterprise deployment.
Mental Model 2: The Data Contract — Governing the API Surface
In traditional software engineering, a Data Contract is the formal, versioned agreement between a data producer and a data consumer. When a microservice exposes an API endpoint, it publishes a contract that defines exactly what data structure will be returned. If the producer changes its response schema, it must version the contract (e.g., v1/clients → v2/clients) to avoid breaking downstream consumers.
In an Airtable ecosystem, the same discipline applies. A sync view in the Parent Base deployed to multiple Child Bases is, architecturally, a published API surface. When a field is renamed without communicating the change downstream, dependent formulas, lookups, and automations silently lose their reference. The change was well-intentioned; the gap was in governance, not in the platform.
Mapping the Data Contract to Airtable
In an enterprise Airtable ecosystem, the Data Contract is the Sync View. The [SYNC_OUT] - Marketing view we configured in Parent-Child Implementation Guide is not just a filtered view; it is a published contract. Its field structure, field names, and filter logic are a versioned agreement with the Marketing Child Base.
A formal Data Contract discipline in Airtable requires three governance rules:
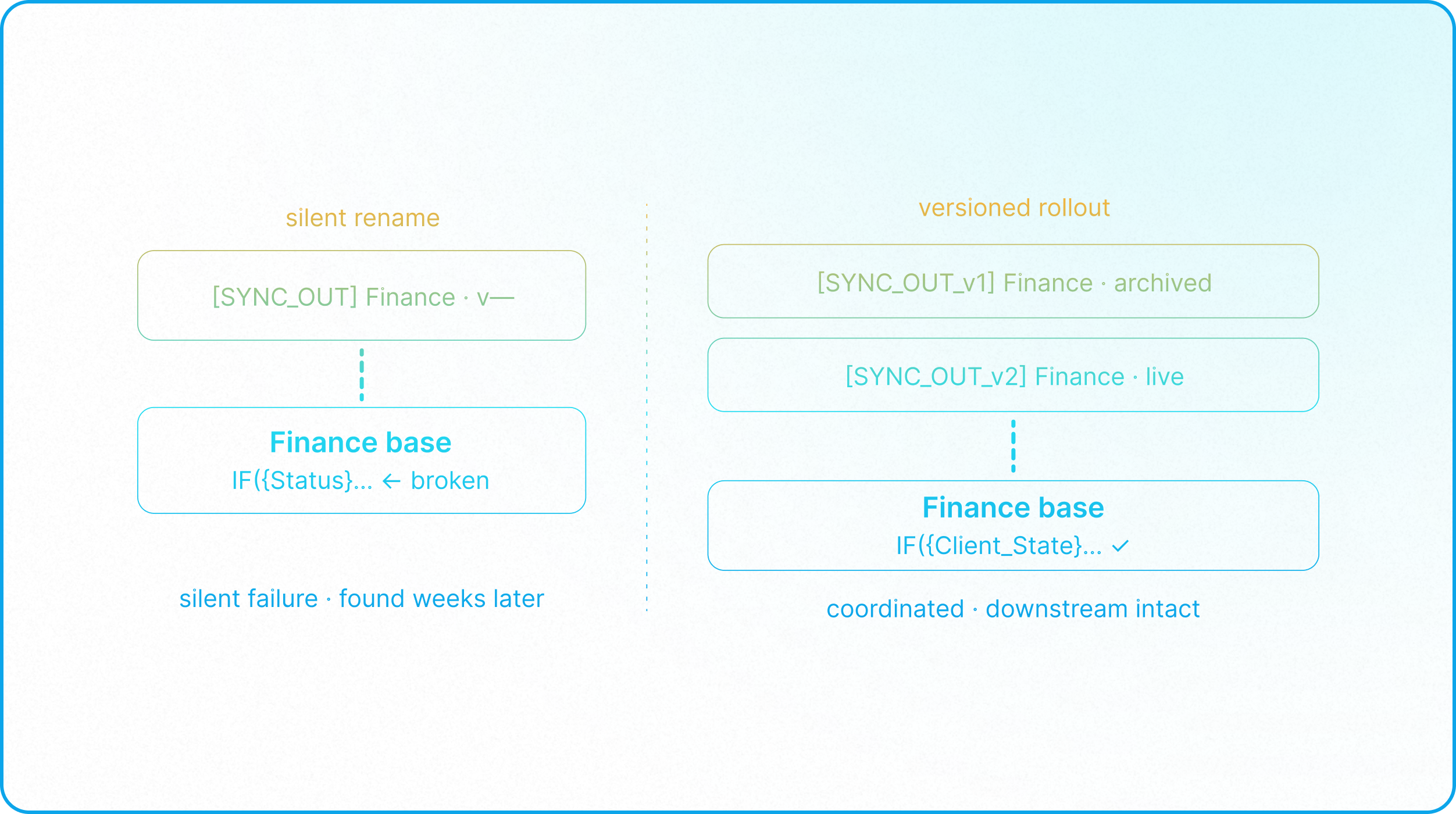
- No Silent Field Renames: Field names in any [SYNC_OUT] view must be treated as published API surface. A rename is a breaking change that requires coordinating with all downstream base owners before execution.
- No Silent Field Type, Option, or Filter Changes: While changing the display name of a field from the source table doesn't carry any changes down to receiving table, mutating field types (e.g., converting a Single Line Text to a Select), altering internal configuration options (e.g., modifying select options), changing which fields are included in the sync payload, or editing view filters will silently break downstream lookup chains, formulas, and background automations. These are the true breaking changes of an Airtable data contract.
- Versioned View Naming: As the data contract evolves, archive the old view ([SYNC_OUT_v1] - Finance) and publish a new, clean contract view ([SYNC_OUT_v2] - Finance). This gives downstream bases time to migrate without operational disruption.
- Contract Documentation: The Data Contracts must be logged in an internal Architecture Registry table: which base is publishing, which base is consuming, which fields are in scope, and what the last reviewed date was.
Mental Model 3: Schema Migration — Evolving Structure Without Disruption
In traditional software engineering, a Schema Migration is a controlled, version-tracked operation that modifies the structure of a live database (adding a column, renaming a table, changing a data type) without corrupting existing data or breaking running applications. Professional engineering teams use tools like Liquibase or Flyway to script and version every structural change to a production database.
Airtable's environment is intentionally more agile: structural changes can be made directly in the interface without scripted deployments. This is a significant operational advantage for fast-moving teams. But it also means that in an enterprise environment with interconnected automations, interfaces, and sync contracts, structural changes require the same deliberate governance that production database migrations demand. As we examined in Architectural Complexity, unmanaged structural changes (field creep, formula chain dependencies, schema fragmentation) carry a real computational and operational cost that compounds silently over time.
The Airtable Schema Freeze Protocol
The Schema Migration principle in traditional database engineering translates directly into a governance protocol in Airtable. Where a SQL engineer would write and version a migration script before altering a production table, the enterprise Airtable architect establishes a Schema Freeze Protocol: a formal process that ensures structural changes are coordinated across all dependent systems instead of being applied spontaneously. The protocol defines:
- The Frozen Zone: All fields in tables consumed by a [SYNC_OUT] view, an Interface, or an Automation are classified as Schema-Frozen. Any structural change to these fields requires a formal review before execution.
- The Change Request Process: A structural modification to the Frozen Zone must be documented: the exact change, the downstream systems affected, the validation procedure, and the restoration plan using Airtable's snapshot history if needed.
- The Deployment Window: Schema changes in high-activity environments are coordinated in advance with the teams whose workflows depend on that data, mirroring standard change management in any enterprise operation.
What the Schema Freeze Protocol accomplishes is a shift in the architect's relationship to change. In a spreadsheet environment, change is spontaneous. In a governed enterprise system, change is a coordinated operation with a clear owner, a documented impact, and a path back if something breaks. That shift in posture, from reactive to deliberate, is exactly what separates a mature enterprise architecture from a base that cannot survive its own growth.
Mental Model 4: Idempotency — Designing for Safe Repetition
In software engineering, an idempotent operation produces the same result no matter how many times it is executed. A well-designed API endpoint that updates a record is idempotent: calling it once or ten times in a row leaves the system in the same final state.
By default, automation logic in any system (Airtable included) requires the architect to explicitly design for it. If an automation fires more than once for the same trigger event (due to a webhook retry, a network delay, or a race condition), it will attempt to execute multiple times. If the intended behavior is to create one invoice or update one record, the architecture must account for this.
Designing Idempotent Automations in Airtable
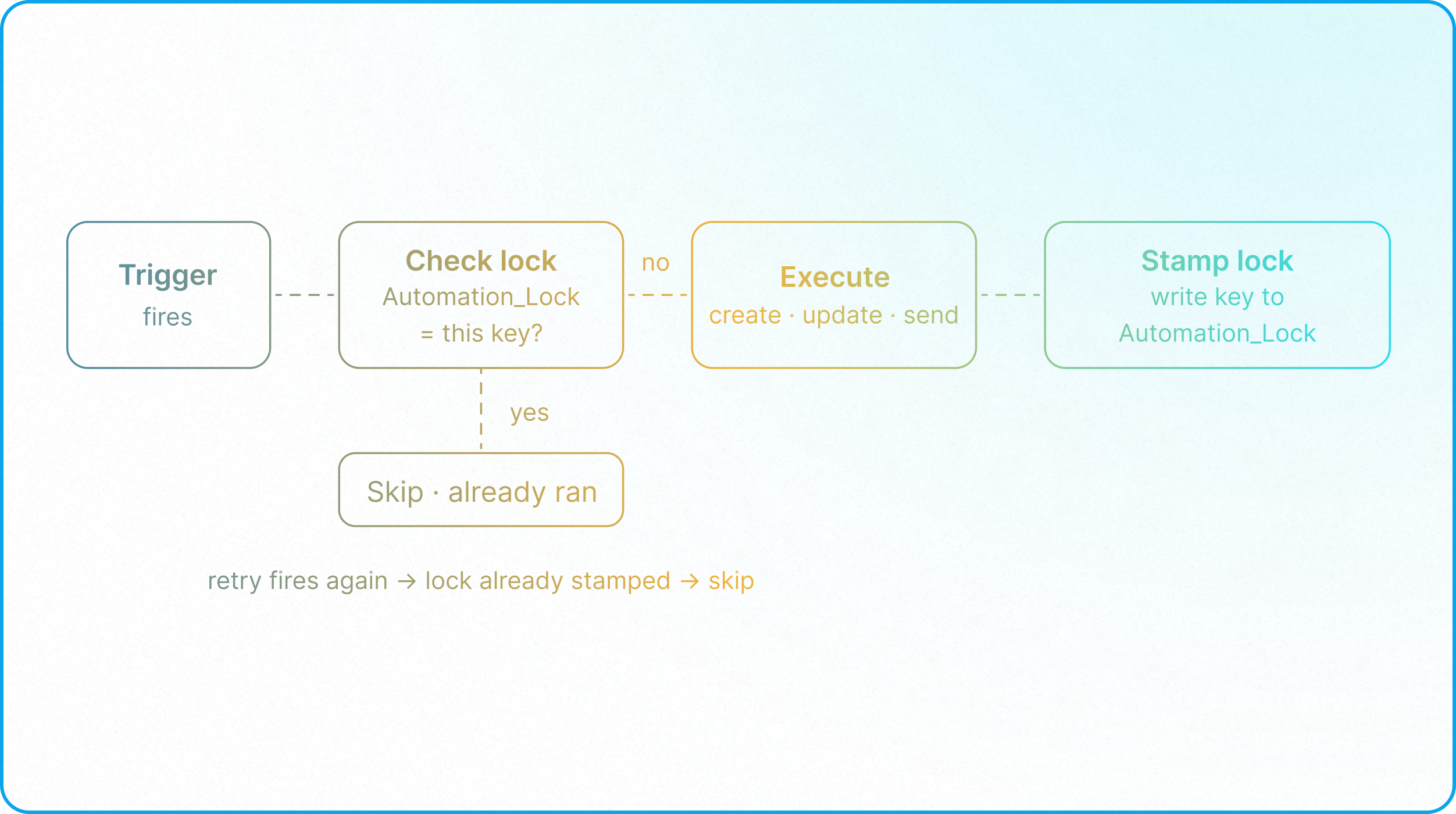
The standard engineering solution is to implement an Idempotency Key: a unique identifier that the system checks before executing an operation. If the key already exists, the operation is skipped.
In Airtable, this is implemented as follows:
- Add a field to your target table named Automation_Lock (Single line text or Formula).
- At the start of the Automation, use a Find Records step to search for any existing record with the same unique identifier (e.g., the RECORD_ID() or an invoice number).
- Only proceed with record creation or API calls if no match is found.
- On completion, write the unique identifier to the Automation_Lock field to permanently mark the operation as completed.
- Define the Idempotency Key: Create a Formula field on the triggering table that generates the unique execution key. For single-execution locks, this can simply be RECORD_ID(). For fine-grained temporal controls (e.g., triggering an automation no more than once a month per record), you can stamp the ID alongside the date: RECORD_ID() & "-" & DATETIME_FORMAT(TODAY(), 'YYYY-MM').
- Create the Writable Lock Field: In the target table, add a field named Automation_Lock. This must be a writable field—either a Single Line Text field (to store the text-based key) or a Linked Record field pointing back to the triggering table—since formula fields are read-only and cannot be written to by an automation.
- Check for Existing Lock: As the second step of your Automation (directly after the trigger), use a Find Records step to search the target table for any existing record where Automation_Lock matches the Formula-generated Idempotency Key from Step 1.
- Conditional Execution: Configure all subsequent actions (e.g., creating a record, executing a script, sending a notification) to run only if the Find Records step in Step 3 found zero matching records.
- Stamp the Lock: On completion of the action, update the target record's Automation_Lock field with the Idempotency Key. This permanently marks the operation as complete, preventing duplicate executions even if the trigger misfires or repeats.
This pattern (standard in any backend engineering environment) transforms Airtable Automations into resilient, enterprise-grade background processes that handle real-world operational complexity with confidence.
The Translation Is the Skill
These four mental models are not independent concepts—they are a chain. The CAP classification determines which data flows require direct API writes and which can use sync. That decision defines the Data Contract: which fields are published, which are protected, and which changes must be coordinated before execution. The Data Contract establishes what Schema-Frozen is. And the Idempotency layer ensures the automations enforcing all of it fire exactly once. The result is an architecture where a data discrepancy has a known audit path, a broken formula has a documented owner and a rollback plan, and a duplicate record is a one-minute fix rather than a two-hour forensic investigation. That is the operational difference between running a system and owning one.
If your team is ready to build at this level, Schedule a Discovery Call with InAir. We audit your current architecture against these engineering standards and design the governance framework that makes your ecosystem resilient, not just functional.


