·
4 minute read
·
4 minute read

In our Enterprise Airtable Architecture Foundations, we established that splitting an overloaded mega-base into dozens of smaller workspaces is dangerous. Without governance, this instinct simply trades a monolithic risk for a decentralized mess: a chaotic web of data silos held together by fragile automations.
However, when an enterprise truly scales, a single base can no longer hold the company's entire operational weight. You must decentralize. You must build an intentional Microservices Architecture.
This post is a deep dive into the exact mechanics of executing that architecture in Airtable. Here is the technical blueprint for separating your data from your workflows without fracturing the system.
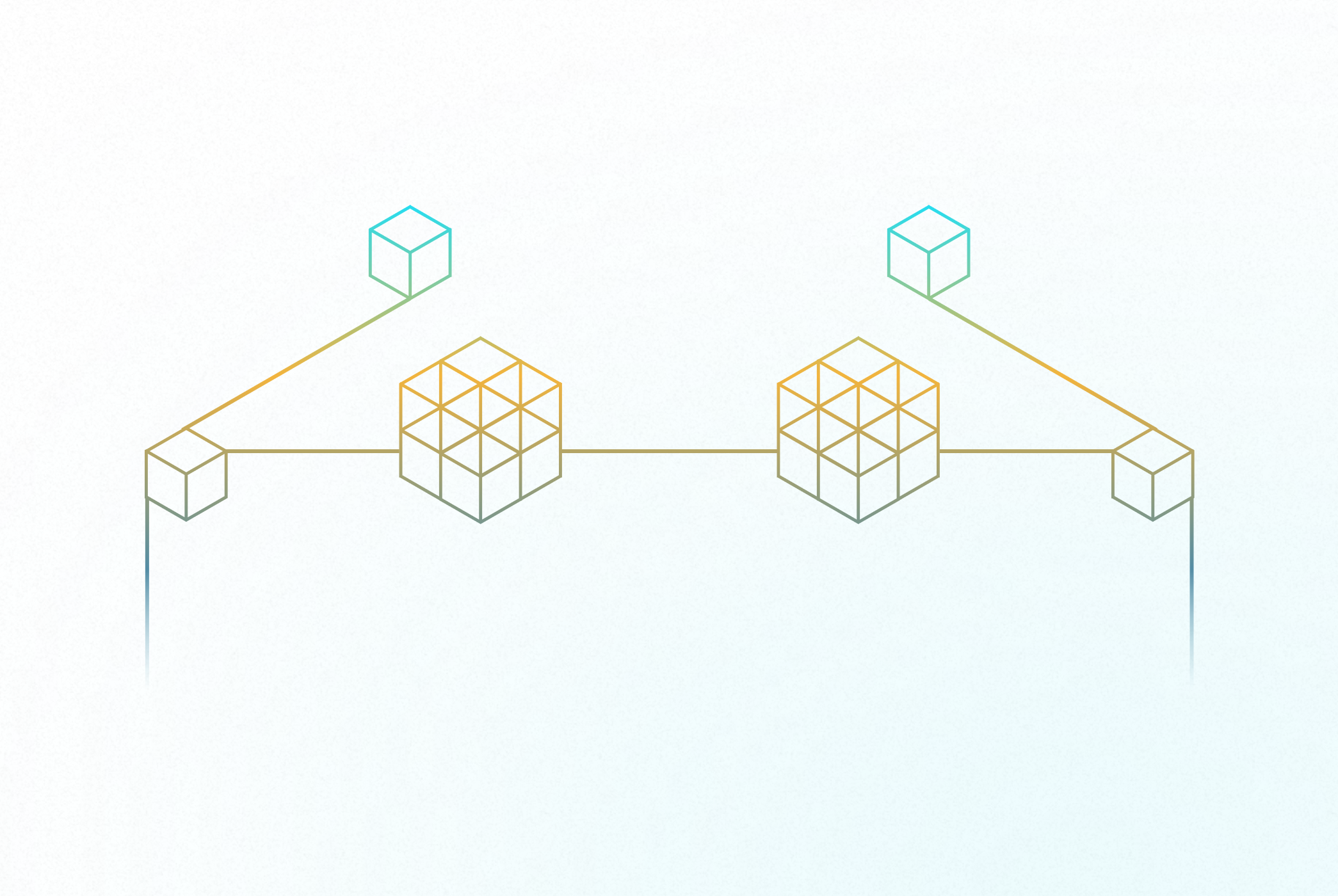
Step 1: Isolate Storage Nodes from Execution Nodes
In an amateur Airtable build (the monolith), data storage and team workflows happen in the same database. In a Microservices Architecture, you must sever this relationship brutally.
You achieve this by creating two distinct types of environments:
- The Storage Node (Parent Base): This base does absolutely nothing but store master data. No daily work happens here. It holds the authoritative Clients table, Products table, and Employees table.
- The Execution Nodes (Child Bases): These are the domain-specific workspaces where teams actually work (e.g., the Marketing Base, the Finance Base). These bases do not own core data. They merely subscribe to it.
By isolating storage from execution, you effectively contain the blast radius of any structural failure. If a citizen developer in the Marketing base accidentally deletes a critical automation, breaks a formula syntax, or triggers an infinite recursive loop, the damage is completely quarantined to their specific Execution Node. The central Storage Node remains untainted, and the Finance team continues operating without interruption. Decoupling these layers is the only way to scale concurrent workflows without risking enterprise-wide data corruption.
Step 2: Enforcing the 'Sync Contract'
To connect the Parent to the Child, citizen developers typically sync the entire master Clients table across the ecosystem. This is a critical architectural vulnerability and one of the most common data integration pitfalls. Syncing the entire database introduces severe UI bloat, forces execution nodes to process unnecessary background updates, and creates a massive security liability by blatantly violating the Principle of Least Privilege (PoLP) by exposing sensitive financial terms to unauthorized teams.
In a mature enterprise architecture, you must govern these connections via strict Sync Contracts. Inside the Parent Base, you never sync the default database view. Instead, the architect builds highly restricted, locked views tailored specifically for the payload required by each department:
The Child bases subscribe only to these hyper-specific endpoints. This enforces the Principle of Minimum Viable Sync.
By restricting the payload, you drastically reduce sync latency and eliminate the risk of accidental data exposure, and this restriction applies to two dimensions simultaneously. First, field restriction: only the columns that the downstream team requires are exposed in the view. Second, record restriction: the view's filter logic determines which records reach the downstream base at all. Finance, for example, has no operational need to see pre-sale leads or free plan customers: only active, paying clients. A properly filtered [SYNC_OUT] view enforces both boundaries natively.
If the Marketing team suddenly requires a client's Tax Status to run a campaign, they cannot bypass governance by simply unhiding a column. They are forced to submit a formal request to alter the central API contract (the Parent's Sync View). This intentional friction is what prevents a decentralized system from devolving into structural chaos.

Step 3: The Closed-Loop Write Mechanism
The most complex challenge in an Airtable Microservices environment is data entry. If the Marketing Base receives client data via a locked, read-only sync, how does a Marketing coordinator update a client's address if they spot an error?
If a citizen developer tries to bypass the read-only restriction by weaving a third-party automation (like Zapier or Make) to copy and paste the edit back to the Parent, it creates a huge potential point of error.
These ad-hoc "write-back" automations introduce significant governance risks. By granting API write access to the master Storage Node to administrators of disparate Child bases, you effectively destroy your security perimeter through human error. Furthermore, these connections are prone to automation misfires and silent execution failures that result in data not being processed, creating an untraceable discrepancy between the Execution Node and the Storage Node.
The only enterprise-grade solution is a Closed-Loop Interface: instead of writing data locally, you must force operators to interact directly with the Storage Node via a governed UI layer:
- The operator clicks a button in their local Marketing Base labeled "Update Client".
- This button opens a centralized Airtable Interface Form that belongs directly to the Parent Base.
- The operator submits the correction via the secure form.
- The submission creates a record in a dedicated Parent 'Intake' table (e.g., [SYS] Change Requests). This triggers a governed automation that validates the request and updates the master record, which then cascades the corrected data back down to the Marketing Base via the Sync Contract.
The Operational Flow
This sequence completely removes third-party automation risk from the equation. When citizen developers rely on Webhooks or external APIs (like Zapier) to patch disconnected bases back together, they introduce severe race conditions and expose the architecture to silent API timeout failures. By forcing all edits through a native, governed Interface intake layer, the update transaction becomes atomic. You maintain absolute data integrity across the entire microservices ecosystem and permanently eliminate the risk of automation errors.
The Architectural Mandate
You cannot build a Microservices Architecture simply by creating more workspaces. When citizen developers clone bases to escape a monolith, they are unknowingly creating unmanaged "Shadow IT" environments. Without deliberate orchestration, this instinct rapidly degrades the database into a fragmented schema where Master Data Management (MDM) becomes impossible.
Airtable is bound by strict, unforgiving compute limits and a finite pool of monthly workspace automation runs. When you attempt to decentralize without strict governance, you inevitably collide with these walls.
Without payload-restricted Sync Contracts, you rapidly max out the record limits of your Execution Nodes with bloated, unnecessary background data. Without a Closed-Loop Interface, you are forced to wire together dozens of bidirectional Webhooks that will relentlessly burn through your automation limits and eventually trigger silent 429 (Too Many Requests) API failures.
Decoupling your Storage Node from your Execution Nodes is not a philosophical preference, but a strict mechanical necessity to scale safely within Airtable's native constraints. By severely restricting the sync payload and routing all write actions through a single atomic Interface form, you reduce background processing to near zero, preserving your API limits and ensuring the database remains lightning-fast regardless of your enterprise's size.
Without this infrastructure, you are not distributing workloads; you are merely accelerating your path toward total system failure. If your team needs help from expert Airtable consultants to execute this transition safely, schedule a Discovery Call with InAir. We engineer the foundational architecture so you can scale your enterprise without ever sacrificing control over your master records.